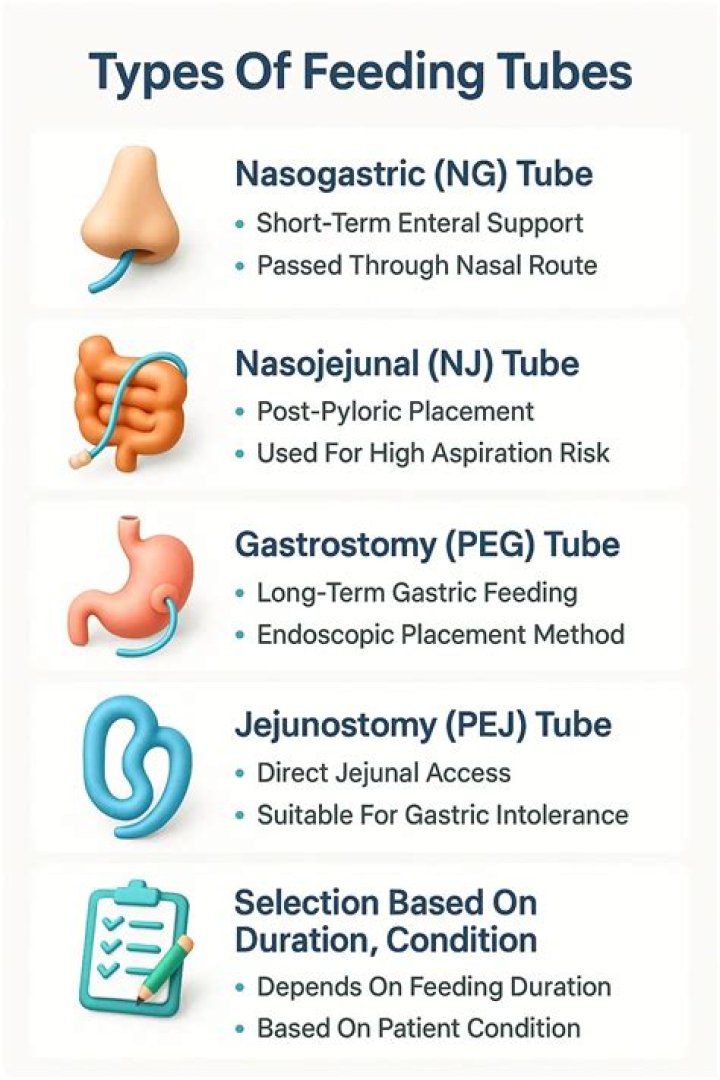
Hidden layer(s) are the secret sauce of your network. They allow you to model complex data thanks to their nodes/neurons. They are “hidden” because the true values of their nodes are unknown in the training dataset. In fact, we only know the input and output. Each neural network has at least one hidden layer.
Where are hidden layers in neural network?
The hidden layer node values are calculated using the total summation of the input node values multiplied by their assigned weights. This process is termed “transformation.” The bias node with a weight of 1.0 is also added to the summation. The use of bias nodes is optional.
What does hidden layer do?
Hidden layers, simply put, are layers of mathematical functions each designed to produce an output specific to an intended result. … Hidden layers allow for the function of a neural network to be broken down into specific transformations of the data. Each hidden layer function is specialized to produce a defined output.
Why hidden layers are used in neural network?
In artificial neural networks, hidden layers are required if and only if the data must be separated non-linearly. Looking at figure 2, it seems that the classes must be non-linearly separated. A single line will not work. As a result, we must use hidden layers in order to get the best decision boundary.What are hidden layers in machine learning?
Hidden layer(s) are the secret sauce of your network. They allow you to model complex data thanks to their nodes/neurons. They are “hidden” because the true values of their nodes are unknown in the training dataset. In fact, we only know the input and output.
What is hidden layer How does hidden layer help in solving XOR problem using Multilayer Perceptron?
An MLP is generally restricted to having a single hidden layer. The hidden layer allows for non-linearity. A node in the hidden layer isn’t too different to an output node: nodes in the previous layers connect to it with their own weights and biases, and an output is computed, generally with an activation function.
Why is it called a hidden layer?
There is a layer of input nodes, a layer of output nodes, and one or more intermediate layers. The interior layers are sometimes called “hidden layers” because they are not directly observable from the systems inputs and outputs.
What is the Ann XOR problem?
The XOR, or “exclusive or”, problem is a classic problem in ANN research. It is the problem of using a neural network to predict the outputs of XOR logic gates given two binary inputs. An XOR function should return a true value if the two inputs are not equal and a false value if they are equal.How many hidden layers does the following neural network have?
Jeff Heaton (see page 158 of the linked text), who states that one hidden layer allows a neural network to approximate any function involving “a continuous mapping from one finite space to another.” With two hidden layers, the network is able to “represent an arbitrary decision boundary to arbitrary accuracy.”
Can a two layer neural network represent the XOR function?A two layer (one input layer, one output layer; no hidden layer) neural network can represent the XOR function. We must compose multiple logical operations by using a hidden layer to represent the XOR function.
Article first time published onHow many layers are required for implementing XOR logic using artificial neural network ANN )?
000011101110
What is 3 layer neural network?
The Neural Network is constructed from 3 type of layers: Input layer — initial data for the neural network. Hidden layers — intermediate layer between input and output layer and place where all the computation is done. Output layer — produce the result for given inputs.
Which neural network is the simplest network in which there is no hidden layer?
The simplest type of feedforward neural network is the perceptron, a feedforward neural network with no hidden units.
Is linear separation possible for XOR?
Perceptron for XOR: XOR is where if one is 1 and other is 0 but not both. Contradiction. … The reason is because the classes in XOR are not linearly separable. You cannot draw a straight line to separate the points (0,0),(1,1) from the points (0,1),(1,0).
What is single layer Perceptron?
A single layer perceptron (SLP) is a feed-forward network based on a threshold transfer function. SLP is the simplest type of artificial neural networks and can only classify linearly separable cases with a binary target (1 , 0).
Why is Mcculloch Pitts neuron widely used in logic functions?
The threshold plays a major role in M-P neuron. There is a fixed threshold for each neuron, and if the net input to the neuron is greater than the threshold then the neuron fires. … The M-P neurons are most widely used in the case of logic functions.
What does the character B represents in the above diagram?
3. What does the character ‘b’ represents in the above diagram? Explanation: More appropriate choice since bias is a constant fixed value for any circuit model.
What is an XOR operation?
The XOR logical operation, or exclusive or, takes two boolean operands and returns true if and only if the operands are different. Thus, it returns false if the two operands have the same value. So, the XOR operator can be used, for example, when we have to check for two conditions that can’t be true at the same time.
What does Hebb's Rule state?
Hebb’s rule is a postulate proposed by Donald Hebb in 1949 [1]. It is a learning rule that describes how the neuronal activities influence the connection between neurons, i.e., the synaptic plasticity. It provides an algorithm to update weight of neuronal connection within neural network.
Which of the following logic gate Cannot be implemented by a perceptron Having 2 inputs?
Answer: NAND is that function which a perceptron cannot handle. NAND is a logic gate which produces an output which is false when all the outputs are true.
Can neural networks learn XOR?
If you are using basic gradient descent (with no other optimisation, such as momentum), and a minimal network 2 inputs, 2 hidden neurons, 1 output neuron, then it is definitely possible to train it to learn XOR, but it can be quite tricky and unreliable.
What is the need of deep neural networks over shallow neural networks?
Both shallow and deep networks are capable of approximating any function. For the same level of accuracy, deeper networks can be much more efficient in terms of computation and number of parameters.
What is epoch in neural network?
An epoch means training the neural network with all the training data for one cycle. In an epoch, we use all of the data exactly once. A forward pass and a backward pass together are counted as one pass: An epoch is made up of one or more batches, where we use a part of the dataset to train the neural network.
What is Theta in neural network?
Theta or weight of a synapse of neuron is multiplied with inputs (or activation of previous layer) and added with a bias to produce action potential as shown in the figure below: Credit and ref: wikipedia. theta θ is fallen out of trend as notation for weight w parameter of an artificial neuron.
What is W and B in neural network?
Weights and Biases. Weights and biases (commonly referred to as w and b) are the learnable parameters of a some machine learning models, including neural networks. Neurons are the basic units of a neural network. In an ANN, each neuron in a layer is connected to some or all of the neurons in the next layer.
Is input layer a hidden layer?
What are Layers in a Neural Network? Input Layer– First is the input layer. This layer will accept the data and pass it to the rest of the network. Hidden Layer– The second type of layer is called the hidden layer.
Which neural network has only one hidden layer between the input and output and information flows only in forward direction?
The feedforward neural network was the first and simplest type of artificial neural network devised. In this network, the information moves in only one direction—forward—from the input nodes, through the hidden nodes (if any) and to the output nodes.
Is threshold a bias?
If you compare a quantity against that value, it’s a threshold. When you move it from one hand side to the other one, it becomes bias.
Why Perceptron Cannot solve nonlinear problems?
In the case of a single perceptron – literature states that it cannot be used for seperating non-linear discriminant cases like the XOR function. This is understandable since the VC-dimension of a line (in 2-D) is 3 and so a single 2-D line cannot discriminate outputs like XOR.
Does XOR provide separability?
Since XOR outputs are not linearly separable. Consider two-input patterns being classified into two classes as shown in the below figure. Each point with either symbol of or represents a pattern with a set of values . Each pattern is classified into one of two classes.