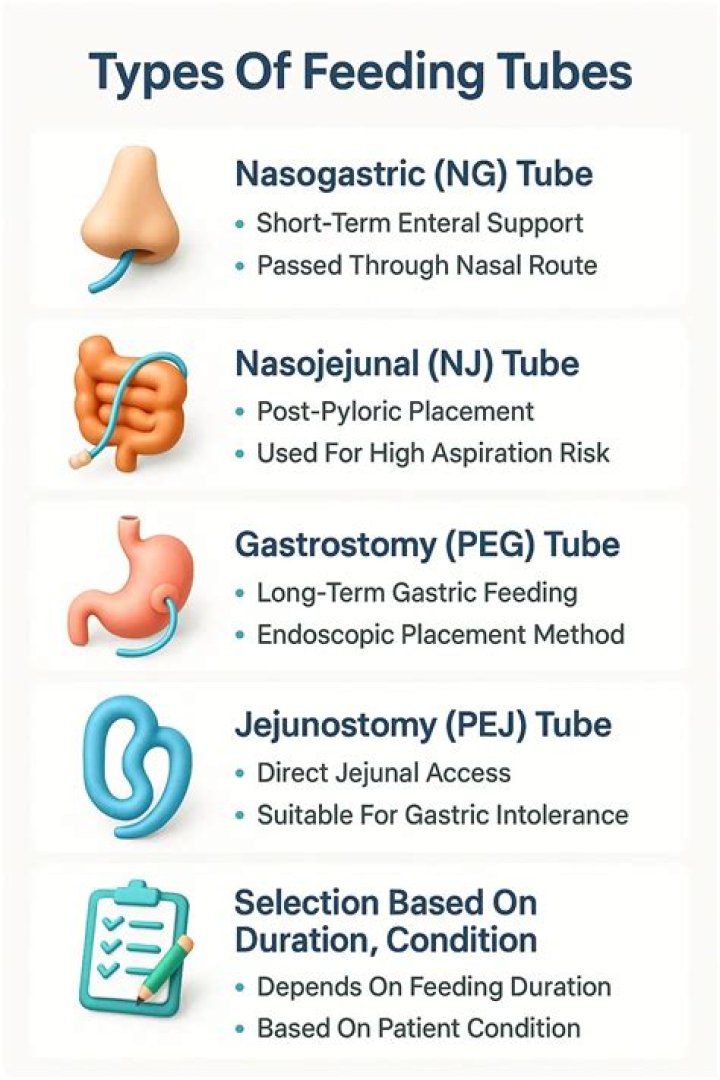
There are three types of anomalies: update, deletion, and insertion anomalies. An update anomaly is a data inconsistency that results from data redundancy and a partial update.
What are the types of anomalies in DBMS?
There are three types of anomalies that occur when the database is not normalized. These are – Insertion, update and deletion anomaly.
What are insertion and deletion anomalies explain?
A deletion anomaly is the unintended loss of data due to deletion of other data. … An insertion anomaly is the inability to add data to the database due to absence of other data. For example, assume Student_Group is defined so that null values are not allowed.
What are different types of anomalies that takes place due to redundant information?
Problems caused due to redundancy are: Insertion anomaly, Deletion anomaly, and Updation anomaly.What is data anomalies in database?
Data anomalies are inconsistencies in the data stored in a database as a result of an operation such as update, insertion, and/or deletion. Such inconsistencies may arise when have a particular record stored in multiple locations and not all of the copies are updated.
What is modification anomalies in database?
Normalization is a process (procedure) of converting database tables to a number of normal forms (NF) in order to avoid redundancy in the database, anomalies of data insertion, editing and deletion. … Modification anomalies include data insertion, editing, and deletion anomalies.
Why do these anomalies exist?
Anomalies are caused when there is too much redundancy in the database’s information. There are three types of Data Anomalies: Update Anomalies, Insertion Anomalies, and Deletion Anomalies. …
What three data anomalies are likely to be the result of data redundancy how such anomalies eliminated?
What three data anomalies are likely to be the result of data redundancy? How can such anomalies be eliminated? The most common anomalies considered when data redundancy exists are: update anomalies, addition anomalies, and deletion anomalies. All these can easily be avoided through data normalization.What kind of anomalies are removed by normalization?
Normalisation is a systematic approach of decomposing tables to eliminate data redundancy and Insertion, Modification and Deletion Anomalies.
What does PK mean in database?Primary Key Constraints A table typically has a column or combination of columns that contain values that uniquely identify each row in the table. This column, or columns, is called the primary key (PK) of the table and enforces the entity integrity of the table.
Article first time published onWhat is Normalisation?
What Does Normalization Mean? Normalization is the process of reorganizing data in a database so that it meets two basic requirements: There is no redundancy of data, all data is stored in only one place. Data dependencies are logical,all related data items are stored together.
What are the three types of anomalies?
There are three types of anomalies: update, deletion, and insertion anomalies. An update anomaly is a data inconsistency that results from data redundancy and a partial update.
What is SQL anomaly?
What is Database Anomaly? Database anomaly is normally the flaw in databases which occurs because of poor planning and storing everything in a flat database. Generally this is removed by the process of normalization which is performed by splitting/joining of tables.
How do you find database anomaly?
To find the outliers in the right and left side of the data you use Q3+1.5(IQR), Q1-1.5(IQR). Also by finding the maximum, minimum, and median of the data you can say whether the anomalies are present in the data or not.
Do anomalies exist?
There exists nonperturbative global anomalies classified by cyclic groups Z/nZ classes also known as the torsion part. It is widely known and checked in the late 20th century that the standard model and chiral gauge theories are free from perturbative local anomalies (captured by Feynman diagrams).
How can anomalies be avoided?
The simplest way to avoid update anomalies is to sharpen the concepts of the entities represented by the data sets. In the preceding example, the anomalies are caused by a blending of the concepts of orders and products. The single data set should be split into two data sets, one for orders and one for products.
What is delete anomaly?
Deletion Anomaly. A deletion anomaly occurs when you delete a record that may contain attributes that shouldn’t be deleted. For instance, if we remove information about the last account at a branch, such as account A-101 at the Downtown branch in Figure 10.4, all of the branch information disappears.
What is Rdbms?
The software used to store, manage, query, and retrieve data stored in a relational database is called a relational database management system (RDBMS). The RDBMS provides an interface between users and applications and the database, as well as administrative functions for managing data storage, access, and performance.
Which one is not an anomaly type which results from redundancy?
Your answer is correct.
What is AK in database?
Alternate Keys (AK) – key associated with one or more columns whose values uniquely identify every row in the table, but which is not the primary key. Primary Foreign Key (PFK) – key which acts as primary key in more than one table which occurs in tables with an identifying relationship.
What does SQL stand for?
SQL (pronounced “ess-que-el”) stands for Structured Query Language. SQL is used to communicate with a database. According to ANSI (American National Standards Institute), it is the standard language for relational database management systems.
What is an AK in SQL?
Introduction to Alternate Key in SQL. The alternate key is a combination of one or more columns whose values are unique. A table consists of one or more Candidate keys, in which one will be Primary Key and rest of the keys, are called as Alternate keys. Alternate Key is not part of the primary key.
What is 1NF 2NF 3NF?
Types of Normal Forms A relation is in 1NF if it contains an atomic value. 2NF. A relation will be in 2NF if it is in 1NF and all non-key attributes are fully functional dependent on the primary key. 3NF. A relation will be in 3NF if it is in 2NF and no transition dependency exists.
What is difference between DBMS and Rdbms?
Database Management System (DBMS) is a software that is used to define, create and maintain a database and provides controlled access to the data. Relational Database Management System (RDBMS) is an advanced version of a DBMS. DBMS stores data as file. RDBMS stores data in tabular form.
What is the difference between Normalising and annealing?
The main difference between annealing and normalizing is that annealing allows the material to cool at a controlled rate in a furnace. Normalizing allows the material to cool by placing it in a room temperature environment and exposing it to the air in that environment.
What are the three normal forms in database?
The database normalization process is further categorized into the following types: First Normal Form (1 NF) Second Normal Form (2 NF) Third Normal Form (3 NF)
What are anomaly detection methods?
Anomaly detection (aka outlier analysis) is a step in data mining that identifies data points, events, and/or observations that deviate from a dataset’s normal behavior. Anomalous data can indicate critical incidents, such as a technical glitch, or potential opportunities, for instance a change in consumer behavior.
Is anomaly detection supervised or unsupervised?
1 Answer. Typically, it is unsupervised.
What is tuples in DBMS?
(1) In a relational database, a tuple is one record (one row). … Typically separated by commas, the values may be parameters for a function call or a set of data values for a database.
What is denormalization in DBMS?
Denormalization is a database optimization technique where we add redundant data in the database to get rid of the complex join operations. This is done to speed up database access speed. Denormalization is done after normalization for improving the performance of the database.
What is the difference between outliers and anomalies?
Outliers are observations that are distant from the mean or location of a distribution. However, they don’t necessarily represent abnormal behavior or behavior generated by a different process. On the other hand, anomalies are data patterns that are generated by different processes.