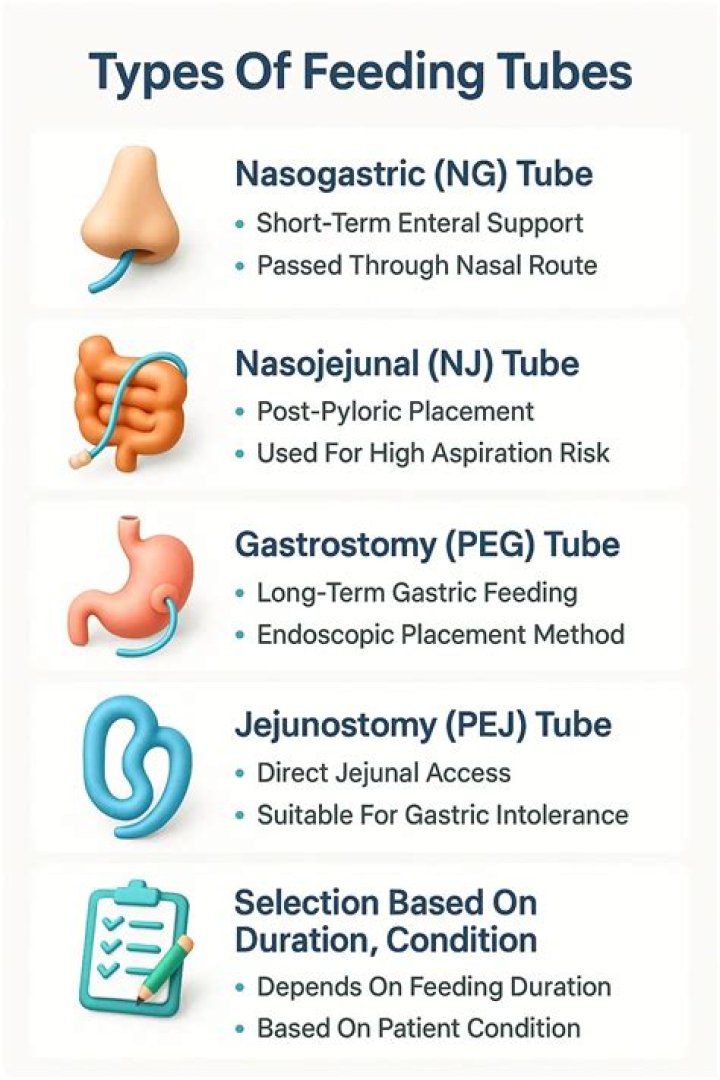
The candidate elimination algorithm incrementally builds the version space given a hypothesis space H and a set E of examples. … The candidate elimination algorithm does this by updating the general and specific boundary for each new example. You can consider this as an extended form of Find-S algorithm.
What is the Candidate Elimination Algorithm?
The candidate elimination algorithm incrementally builds the version space given a hypothesis space H and a set E of examples. … The candidate elimination algorithm does this by updating the general and specific boundary for each new example. You can consider this as an extended form of Find-S algorithm.
Why do we use candidate elimination method?
The objective of the Candidate Elimination Algorithm is to find all describable rule that are consistent with the observed training examples.
Where is Candidate Elimination Algorithm used?
Candidate Elimination Algorithm is used to find the set of consistent hypothesis, that is Version spsce.What is the difference between find-s and Candidate Elimination Algorithm?
FIND-S outputs a hypothesis from H, that is consistent with the training examples, this is just one of many hypotheses from H that might fit the training data equally well. The key idea in the Candidate-Elimination algorithm is to output a description of the set of all hypotheses consistent with the training examples.
What are the most important machine learning algorithms?
- Linear Regression. …
- Logistic Regression. …
- Decision Tree. …
- SVM (Support Vector Machine) Algorithm. …
- Naive Bayes Algorithm. …
- KNN (K- Nearest Neighbors) Algorithm. …
- K-Means. …
- Random Forest Algorithm.
What is inductive bias in candidate elimination algorithm?
Inductive bias refers to the restrictions that are imposed by the assumptions made in the learning method. … The inductive bias of the candidate elimination algorithm is that it is only able to classify a new piece of data if all the hypotheses contained within its version space give data the same classification.
What are types of machine learning?
These are three types of machine learning: supervised learning, unsupervised learning, and reinforcement learning.What is inductive bias in ML?
The inductive bias (also known as learning bias) of a learning algorithm is the set of assumptions that the learner uses to predict outputs of given inputs that it has not encountered. In machine learning, one aims to construct algorithms that are able to learn to predict a certain target output.
Will the candidate elimination algorithm converge to the correct hypothesis?Remarks on Version Spaces and Candidate-Elimination The version space learned by the CANDIDATE-ELIMINATION algorithm will converge toward the hypothesis that correctly describes the target concept, provided (1) there are no errors in the training examples, and (2) there is some hypothesis in H that correctly describes …
Article first time published onWhat is are Advantage's of locally weighted regression?
Locally weighted regression learns a linear prediction that is only good locally, since far away errors do not weigh much in comparison to local ones.
What are the limitations of the find-s algorithm that are handled by the candidate elimination algorithm?
Limitations of Find-S Algorithm There is no way to determine if the hypothesis is consistent throughout the data. Inconsistent training sets can actually mislead the Find-S algorithm, since it ignores the negative examples.
Where is find s algorithm used?
FIND S Algorithm is used to find the Maximally Specific Hypothesis. Using the Find-S algorithm gives a single maximally specific hypothesis for the given set of training examples.
What is target concept in machine learning?
A target function, in machine learning, is a method for solving a problem that an AI algorithm parses its training data to find. Once an algorithm finds its target function, that function can be used to predict results (predictive analysis).
Why K Nearest Neighbor algorithm is lazy learning algorithm?
Why is the k-nearest neighbors algorithm called “lazy”? Because it does no training at all when you supply the training data. At training time, all it is doing is storing the complete data set but it does not do any calculations at this point.
What is CNN inductive bias?
The group equivariance in convolutional neural networks is an inductive bias that helps in the generalisation of the networks. … This layer increases the expressive capacity of the Convolutional Neural Network without increasing the number of parameters.
Why is inductive bias important for a machine learning algorithm?
An inductive bias allows a learning algorithm to prioritize one solution (or interpretation) over another, independent of the observed data. […] Inductive biases can express assumptions about either the data-generating process or the space of solutions.
What are the steps in designing a machine learning problem explain with the Checkers problem?
- The exact type of knowledge to be learned (Choosing the Target Function)
- A representation for this target knowledge (Choosing a representation for the Target Function)
- A learning mechanism (Choosing an approximation algorithm for the Target Function)
What is hypothesis in machine learning?
Hypothesis in Machine Learning is used when in a Supervised Machine Learning, we need to find the function that best maps input to output. This can also be called function approximation because we are approximating a target function that best maps feature to the target.
What are the five popular algorithms we use in machine learning?
- Linear Regression.
- Logistic Regression.
- Decision Tree.
- Naive Bayes.
- kNN.
Which algorithm is best for prediction?
1 — Linear Regression Linear regression is perhaps one of the most well-known and well-understood algorithms in statistics and machine learning. Predictive modeling is primarily concerned with minimizing the error of a model or making the most accurate predictions possible, at the expense of explainability.
Which algorithm is used most?
- Decision Tree.
- SVM.
- Naive Bayes.
- kNN.
- K-Means.
- Random Forest.
- Dimensionality Reduction Algorithms.
- Gradient Boosting algorithms. GBM. XGBoost. LightGBM. CatBoost.
What is restriction bias?
A restriction bias is an inductive bias where the set of hypothesis considered is restricted to a smaller set. …
What is preference bias?
A preference bias is when a learning algorithm incompletely searches a complete hypothesis space. It chooses which part of the hypothesis space to search. An example is decision trees.
Is high bias Overfitting?
A model that exhibits small variance and high bias will underfit the target, while a model with high variance and little bias will overfit the target. A model with high variance may represent the data set accurately but could lead to overfitting to noisy or otherwise unrepresentative training data.
What is ML and its application?
Machine learning is an application of artificial intelligence (AI) that provides systems the ability to automatically learn and improve from experience without being explicitly programmed. Machine learning focuses on the development of computer programs that can access data and use it to learn for themselves.
What is classification and regression in machine learning?
That classification is the problem of predicting a discrete class label output for an example. … That regression is the problem of predicting a continuous quantity output for an example.
Who is the father of machine learning?
Geoffrey Hinton CC FRS FRSCFieldsMachine learning Neural networks Artificial intelligence Cognitive science Object recognition
What are the conditions for the candidate elimination algorithm to converge to the correct hypothesis?
The version space learned by the Candidate- Elimination Algorithm will converge toward the hypothesis that correctly describes the target concept provided: (1) There are no errors in the training examples; (2) There is some hypothesis in H that correctly describes the target concept.
What is list then algorithm?
The List-Then-Eliminate Algorithm is another learning algorithm. This algorithm begins with a full Version Space (a list containing every hypothesis in H). Then for every training example, we remove every hypothesis (from the Version Space) that does not agree with the training example.
Is data mining a ML?
Data mining is used on an existing dataset (like a data warehouse) to find patterns. Machine learning, on the other hand, is trained on a ‘training’ data set, which teaches the computer how to make sense of data, and then to make predictions about new data sets.